Compétence
Installer de façon autonome ses propres instruments de travail et les utiliser correctement en veillant à la sécurité.
Objectifs opérationnels
- Connecter divers terminaux utilisateur (appareils périphériques).
- Mettre en service les terminaux utilisateur.
- Vérifier l’état actuel des terminaux utilisateur et les mettre à jour si nécessaire (update).
- Identifier les données commerciales pertinentes pour la sécurité et, si nécessaire, définir des mesures appropriées.
- Installer et configurer des logiciels d’applications.
- Sauvegarder de façon autonome ses propres données et les données de projet.
Descriptif complet du module 286…
Support pdf
Table des matières
- Qu’est-ce qu’un ordinateur ?
- Histoire
- Matériel
- Logiciel
- Système d’exploitation
- Applications
- Licence logicielle
- Le nuage – cloud computing
- La sécurité informatique
- La protection des données
- La sauvegarde des données
Avant de commencer, il est bon de réfléchir à ce qui semble une évidence:
Qu’est-ce qu’un ordinateur ?
=> Ajoutez des mots-clés….. par l’intelligence collective, on trouvera…

Qu’est-ce qu’un ordinateur ?
On sait tout ce qu’est un ordinateur en pratique. On en utilise tellement partout. Mais trouver une définition c’est encore autre chose.
Un ordinateur, c’est une machine universelle programmable.
Un grille pain, une TV, une machine à laver, un lecteur mp3, une voiture, un aspirateur, ce sont des machines. Mais ce sont des machines spécialisées. Un grille pain, il grille du pain, une TV elle capte et affiche des programmes TV.
Un ordinateur il fait quoi ? … heu… c’est vaste…. Tout ?
C’est à peu près ça. Ce qui caractérise un ordinateur c’est que c’est une machine qui n’a pas été conçu pou une tâche en particulier. Où plutôt ça tâche c’est d’accueillir et de faire tourner le programme qui en a besoin.
Un programme ? C’est quoi ça ?
Ma machine à laver a aussi plusieurs programmes de lavage. C’est un ordinateur ?

La notion de programme apporte une dimension supplémentaire. Celle du logiciel. Beaucoup de machines spécialisées actuelles ont de petits composants logiciels. Les programmes de ma machine à laver où ma machine à coudre ne sont pas très évolués. Ils sont souvent introduits par le constructeur et on ne les change plus.
Histoire
Les grands ancêtres
La machine d’Anticythère est un calculateur astronomique. On peut lui donner une date et la machine nous donne la position des planètes ce jour là.
La machine d’Anticythère a été retrouvée en 1901 dans l’épave d’un bateau romain. La datation de cette machine remonte à avant -87. Ce qui est très étonnant pour une machine d’horlogerie si précise.


La Pascaline
La Pascaline est la première machine à calculer mécanique. Elle a été imaginée en 1642 par Blaise Pascal et réalisée 3 ans plus tard.
Le but était d’aider son père à faire des calculs de comptabilité.

La machine de Babbage
La machine de Babbage est le vrai premier ordinateur. Mais il n’a jamais été fini.
Charles Babbage l’a imaginée en 1834. En parallèle c’est la comtesse Ada Lovelace qui développe pour cette machine le premier algorithme de programmation de l’histoire, devenant la première personne à programmer un ordinateur.

La machine de Babbage utilise des cartes perforées comme lecteur de données externes. Ces cartes sont issues des techniques du métier à tisser inventée en 1725 par le lyonnais Basile Bouchon.
Ce type de programmation est popularisé dès 1801 par le métier à tisser Jacquard. Les cartes perforées sont utilisées pour décrire les motifs des tissus à tisser.
Cette programmation est tout de même rudimentaire. Elle est séquentielle. Ce n’est que depuis Ada Lovelace que les branchements conditionnels sont inventés. (if… then… else…)

L’ordinateur électromécanique
Ensuite la chronologie de l’informatique s’emballe. L’étape suivante passe à l’ordinateur électro-mécanique. On a plus besoin de machine à vapeur pour faire tourner l’ordinateur. Il devient une machine électrique.
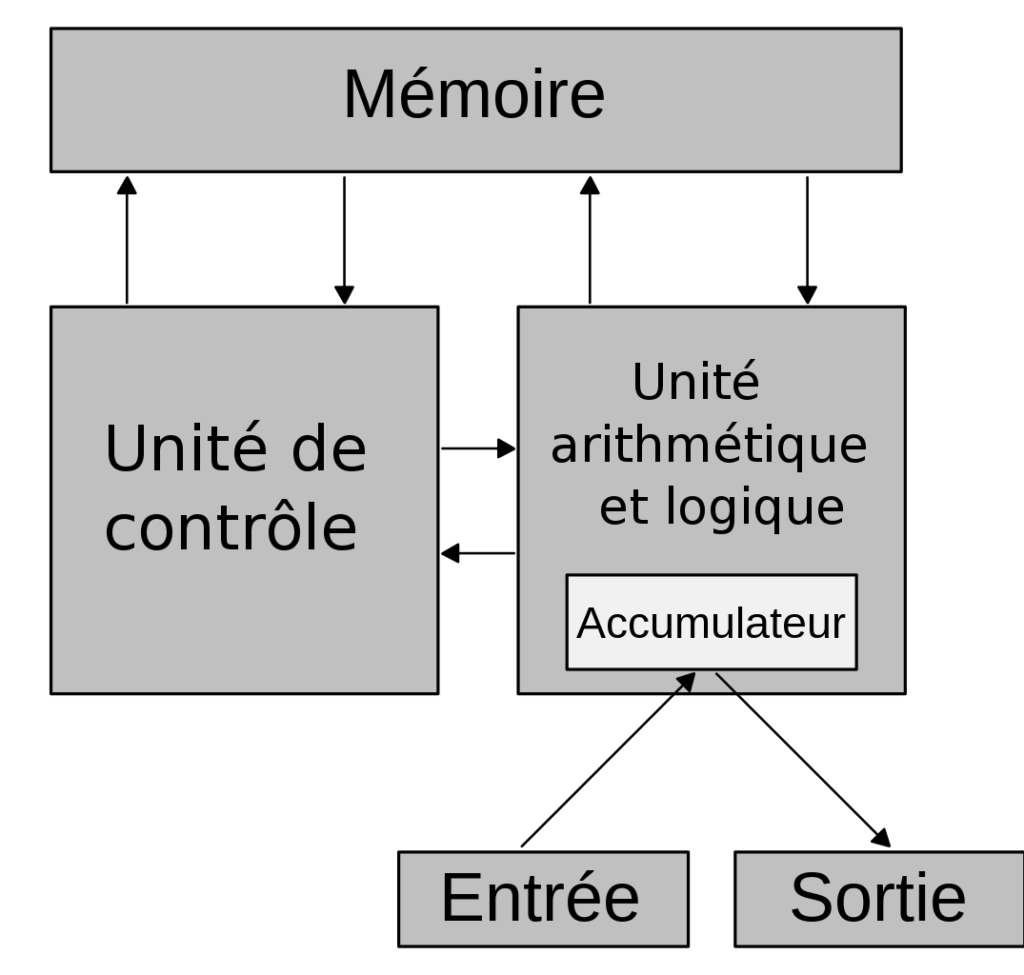
En 1936, Alan Turing invente le concept de machine abstraite. C’est l’architecture d’un ordinateur capable de tout faire. Il faut des entrées, des sorties, une mémoire, un jeu d’instruction, un programme.
En 1939, IBM commence à construire le Mark I, il est fonctionnel en 1944.

L’ordinateur électronique
En 1945, l’ENIAC est le premier ordinateur entièrement électronique pouvant être Turing-complet.
L’ENIAC est remarquablement volumineux : il contient 17 468 tubes à vide, 7 200 diodes à cristal, 1 500 relais, 70 000 résistances, 10 000 condensateurs, 300 voyants lumineux pour l’affichage continu de l’état des registres, et environ 5 millions de soudures faites à la main.

L’ENIAC se programme par des câbles.
En 1947, il est modifié pour adopter l’architecture Von Neuman. La mémoire enregistre tout autant le programme à exécuter que les données à traiter.
Depuis tous les ordinateurs sont basés sur cette architecture.
1947, c’est aussi l’année de l’invention du transistor. C’est ce qui va permettre de créer des interrupteurs miniaturisés et ainsi d’avoir un ordinateur dans sa poche.

L’ordinateur central et ses terminaux
En 1956, IBM sort le premier disque dur : le RAMAC 305. Il pouvait stocker 5 Mo de données.

Depuis le milieu des années 1960, pendant toutes les années 1970 et un peu des années 1980, c’est le règne des gros ordinateurs centraux. (IBM, PDP, VAX)
Ce sont des « mastodon » détenus principalement par des (très) grandes entreprises et des universités.

Dans ce modèle de fonctionnement, il y a un seul ordinateur pour toute l’organisation et ses utilisateurs se connectent dessus via un terminal informatique. En bref, un terminal c’est juste un clavier et un écran qui permettent de lancer des lignes de commande à distance sur un ordinateur central.
(Le terminal a débuté avec des téléscripteurs – machine à écrire en réseau – pour devenir un micro-ordinateur, puis de nos jours juste une application TTY… d’où le nom de puTTY)

Dans les années 1970, les réseaux informatiques sont très présents. Les ordinateurs sont massivement multi-utilisateurs.
C’est dans ce concept que le e-mail s’est développé. Comme tous les utilisateurs sont sur le même ordinateur, il est facile de laisser un message à un autre utilisateur. Puis en 1971, Ray Tomlinson a proposé d’utiliser le symbole @ pour séparer le nom d’utilisateur du nom de la machine. Ainsi il est possible d’envoyer un message sur un autre ordinateur !
En 1971, y a déjà 23 ordinateurs qui sont reliés sur Arpanet.

Le concept d’ordinateur central n’a pas totalement disparu. Il existe encore des application sur des mainframes dans certaines banques et assurance, mais aussi dans des aéroports. Ce type d’ordinateur est utilisé surtout pour sa grande fiabilité et une sécurité élevée.
La microinformatique
Avec la miniaturisation, les années 1970 voient l’émergence de la micro-informatique. L’ordinateur peut devenir individuel, il n’occupe plus une salle entière.
En 1971, Intel commercialise le premier microprocesseur, le Intel 4004.

En 1972, Kenneth Thompson et Dennis Ritchie nos geeks barbus préférés créent le langage C. Un langage de programmation très populaire. (Ils sont aussi à l’origine de UNIX et de l’UTF-8, on y reviendra, sans eux impossible de lire cette page.)

En 1973, le Micral est considéré comme le premier micro-ordinateur. Il a été conçu par François Gernelle dans un bureau d’ingénieur français pour répondre à une commande de l’INRA pour un système de mesure et de calcul de l’évapotranspiration des sols.
Le Micral est basé sur un processeur 8bits Intel 8008 cadencé à 500KHz. Il dispose de 2ko de RAM.
Cet ordinateur se programme via un téléscripteur.

En 1975 Ed Roberts, pour éviter la faillite, réoriente son usine de fabrication de calculatrice en Kit ver la création d’un micro-ordinateur en kit, le Altair 8800.
Dans son plan financier, il avait dit à son banquier qu‘il en vendrait 800, un mois après le lancement il recevait 250 commandes par jours !
Ce succès est du au fait que l’Altair 8800 a fait la une du magazine Popular electronics.

Cette une a aussi attiré deux étudiants: Bill Gates et Paul Allen.
Ils proposent à Ed Roberts de fournir « Altair Basic » à l’ordinateur Altair 8800. Il s’agit d’un interpréteur du langage de programmation BASIC.
Roberts accepte et la nouvelle société Micro-soft est créé et gagne 35$ par copie vendu de son « Altair Basic« . (L’altair est vendu 397$)
En 1977 Ed Roberts vend son entreprise, reprend des études et devient médecin !

Le succès de cet ordinateur montre qu’il a une forte envie de nombreux bricoleur d’avoir leur propre ordinateur à un prix accessible et pas un ordinateur d’université hors de prix.
Du coup, beaucoup étaient prêts à en acheter un, mais pour quoi faire ?
L’Altair 8800 était une solution, mais on cherchait le problème !!
C’est là que les clubs d’informatique ont été un lieu d’émulation, notamment le Home brew computer club. C’est lors de la présentation d’un Altair que Steve Wozniak a eu l’envie de créer son propre ordinateur.
En 1976, Steve Jobs et Steve Wozniak crée leur entreprise Apple computer qui vend leur premier micro-ordinateur, l’Apple 1.

L’Apple 1 était révolutionnaire dans le sens qu’il comportait un clavier et un écran ! … Ce qui nous parait logique, mais était loin d’être le cas à l’époque.
L’Altair 8800 par exemple se programmait avec des interrupteurs et utilisait des LED rouge pour l’affichage.
En 1977, l’Apple II remplace la version 1. On a là un véritable micro-ordinateur comme on l’entend de nos jours.
Le succès de l’Apple II doit beaucoup au tableur VisiCalc disponible depuis 1979. C’est là que l’informatique passe des geek aux petites entreprises.

En 1981, IBM lance un micro-ordinateur à architecture ouverte, l’IBM PC. D’autres fabricants peuvent crées des compatibles PC. C’est cette famille que l’on trouve encore sous le nom commun de PC, le Personal Computer.
Le PC tourne avec un interpréteur du langage de programmation BASIC et fonctionne sur le système d’exploitation MS-DOS fourni par Microsoft.

Tout ces standards sont en fait un sacré concours de circonstance.
IBM était LE mastodonte de l’informatique, mais comme tout mastodonte, incapable de bouger vite. Donc l’arrivée de la micro-informatique et semé un vent de panique.
Le PC a été la réponse la plus rapide possible proposée par un labo marginal d’IBM. Contrairement à la philosophie d’IBM, rien n’a été fait en interne. Le PC n’est qu’un assemblage de composants achetés à l’extérieur.
Pour le système d’exploitation l’idée était aussi de sous traiter. IBM pensait utiliser le standard du moment CP/M. Mais son concepteur Gary Kildall a refusé les conditions contractuelles de IBM pour une histoire d’accord de confidentialité et de redevances.
C’est donc Bill Gates qui propose à IBM une solution. Mais il ne l’a pas encore vraiment. Il va donc acheter le système QDOS (Quick and Dirty OS), pour 50 000$ et le revend à IBM sous le nom de MS-DOS avec un système de redevances à chaque copie.
On a donc là, les standards et les entreprises qui règnent toujours sur le monde de l’informatique.
Cependant, l’histoire est pleine d’autres entreprises et système qui ont été parfois très populaire, comme le Commodore 64 qui détient le record du modèle d’ordinateur le plus vendu.
Sur le Commodore 64 il y avait des cassettes (audio) comme support mémoire externe.
C’était pas très rapide ! Voici une vidéo qui montre le temps que ça prenait pour charger un jeu.
En 1978, avant le PC de IBM, le SMAKY 6 était déjà commercialisé. Il s’agit d’un ordinateur made in Switzerland. Conçu et construit à l’EPFL.

Toute la famille SMAKY a fait son chemin dans les écoles en Suisse, ce jusqu’à la fin des années 1990.
En 1983, le Lisa de Apple, est le premier ordinateur a être commercialisé avec une souris et une interface utilisateur graphique. (avec le glisser-déposer d’icon qu’on doit à Jef Raskin)

Hormis les expérimentations du labo du Xerox Parc qui ont inspiré Steve Jobs, c’est le premier ordinateur qui utilise la métaphore du bureau. L’utilisateur voit un bureau, il ouvre des dossiers, voit des fichiers sous forme d’icône qu’il affiche dans une fenêtre et peut les jeter à la corbeille.
Cependant le prix du Lisa est tellement élevé – 10 000$ – que c’est un flop.
C’est finalement en 1984 avec le Macintosh que l’interface graphique va se populariser largement.
C’est le lancement de toute la famille des Mac…
En 1984 on a le SMAKY 100, ordinateur Suisse qui est déjà équipé d’une souris. En effet, Jean-Daniel Nicoud, l’inventeur du smaky est aussi l’inventeur de la première souris optique.
Le smaky 100 dispose d’un processeur Motorola 68000 tout comme le Macintosh.

En 1985 Microsoft sort Windows 1.0. Ce n’est pas tout à fait un système complet, mais une surcouche graphique de MS-DOS, volontairement limitée pour éviter de violer des brevets d’Apple !
L’ère de l’Internet et du web
En 1991, après 3 ans de travail au CERN, Tim Berners-Lee et Robert Cailliau publie leur système hypertexte. Le web est né. (protocole HTTP navigateur World Wide Web et format HTML)
Le Web, c’est LE service qui va populariser Internet. (L’Internet, c’est l’autoroute et le web c’est les maisons qu’on peut visiter grâce à la route qui les relie). Le protocole TCP-IP trouve son origine au début des années 1970 et est adopté en 1983 sur Arpanet qui devient Internet.

La même année 1991, Linus Torvalds publie sont premier noyau libre: Linux 0.01.
La fin des années 1990 voit les limites des systèmes de micro-informatique qui sont conçus pour être mono-utilisateur et avec un réseau en option.
C’était bien le concept du PC, le Personal Computer. De nouveaux systèmes sont développés sur la base des concepts des années 1970 pour réintégrer la couche réseau en bas niveau.
L’exemple le plus radical, c’est Apple qui abandonne son system classic, rachète NextStep (et Steve Jobs au passage) pour créer les fondations de MacOs X qui sort en 2001.
La fin des années 1990 voit aussi la libéralisation du marché des télécom avec l’arrivée de la téléphonie mobile et des connexions Internet permanentes.

Les appareils photos numériques remplacent les appareils à film argentiques traditionnel. Le monde se numérise, on parle de « digitalisation ».

En 2001, toujours Apple sort son baladeur mp3, l’iPod. Un nom propre qui devient un nom commun et remplace le Walkman dans l’imaginaire.
L’ère du smartphone
En 2007, Apple lance l’iPhone.
C’est le premier smartphone qui a un navigateur web vraiment utilisable.
Steve Jobs a influé sur les opérateurs de télécom en les obligeant à fournir un abonnement de données au forfait pour ne pas exploser la facture de la navigation web sur iPhone et pour garantir une bonne expérience utilisateur.
Après la révolution de l’interface graphique utilisateur popularisée par Apple, après la révolution du smartphone popularisée par Apple, est-ce que l’on aura droit à une nouvelle révolution dans l’interface utilisateur ?
Est-ce que c’est encore une fois Apple qui va amener une nouvelle ère ?
C’est peut être le cas avec le Apple Vision pro, dévoilé en juin 2023.

Le Métavers en réalité virtuelle promis par Facebook ne progresse pas. Le soucis c’est qu’il y a un tiers des gens qui sont malade en portant un casque.
Ainsi Apple propose une solution intermédiaire: la réalité augmentée.
On superpose des images à la vision courante de son environnement.
Google avait déjà le projet avec ses Google Glasses, mais le projet a silencieusement été abandonné en 2015.
On verra si le projet d’Apple prend. L’histoire nous montre qu’Apple ne fait pas des annonces dans le vide. Généralement, c’est que le projet est déjà très avancé.
Mais le dernier mot restera encore au public de savoir si il adopte l’objet et le concept ou non ?
Car finalement on peut déjà utiliser de la réalité avec un smartphone. C’est le cas avec les app pour obtenir les noms des étoiles ou des montagnes. Mais aussi pour couper un gâteau en 7 parts !

Ordinateur quantique
L’ordinateur quantique est une approche toute différente de l’informatique. C’est une approche qui utilise les propriétés de superposition d’état de la physique quantique. Une particule peut être dans plusieurs état en même temps.
A la place des bits, l’ordinateur quantique utilise des qbits.
C’est l’ordinateur quantique Zuchongzhi 2 qui depuis 2021 détient le record de puissance en manipulant 66 qbits.
Mais depuis IBM a sorti un ordinateur quantique de 127 Qbits et prévoit de doubler le nombre de Qbits tous les 18 mois… le retour de la loi de Moore !
Voici une émission de 2019 tout a fait passionnante à propos de la manière dont la France se positionne dans le marché de l’ordinateur quantique. Ça prend sérieusement forme avec des centres de calcul dédié.
Sommes nous un ordinateur biologique ?
Voici une animation qui montre le fonctionnement de notre biologie. L’ADN (software) est décodé converti en ARN. Nous avons aussi une partie logicielle et une partie matérielle.
L’ADN correspond à une mémoire de masse (disque dur)
L’ARN correspond à une mémoire de travail volatile (RAM)
La crise Covid a démocratisé au grand public des notions sur les outils actuel de la génétique, notamment la technique PCR qui permet d’amplifier de l’ADN, donc une sorte de mécanisme de copie.
Ainsi que la technique des vaccins à ARN-Messager. Voici un article qui détaille la création du vaccin de BioNtech à destination des informaticiens.
Matériel
Après ce grand tour historique, entrons dans le concret du quotidien actuel, à quoi ressemble un ordinateur « standard » de nos jours ?
Exercice: quels sont les composants de base d’un ordinateur ?
Nommez les différents composants et leur fonction.
=> Pour faire l’exercice tous ensemble…. https://app.wooclap.com/CPORDI
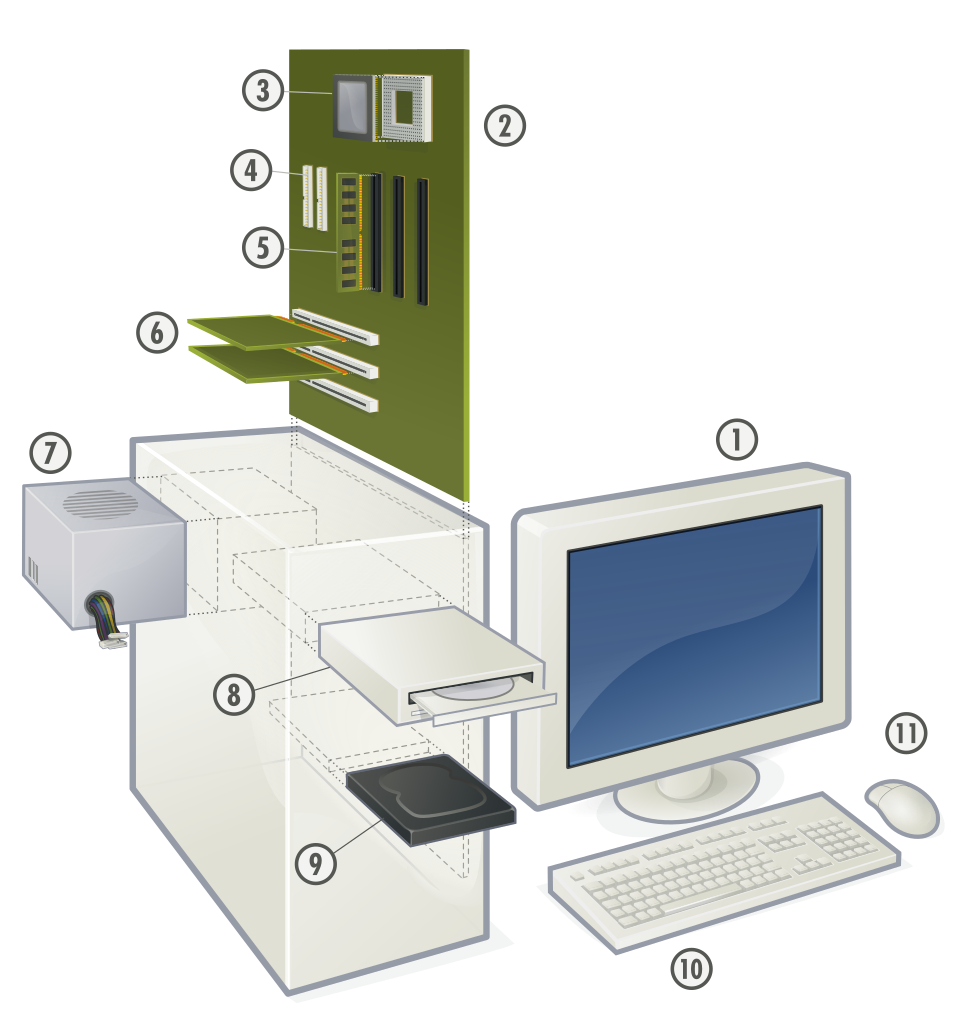
Réponses: composants d’un ordinateur
1 : Écran
2 : Carte mère – Le circuit imprimé qui supporte les composants de l’ordi
3 : Processeur – l’unité de calcul
4 : Parallèle ATA – connecteur pour disque dur (remplacé par SATA)
5 : Mémoire vive (RAM) – mémoire de travail
6 : Connecteurs d’extensions (PCI) : Carte Graphique, Carte Son, Carte réseau, etc.
7 : Alimentation électrique
8 : Lecteur de disque optique (CD / DVD)
9 : Disque dur, disque électronique SSD
10 : Clavier
11 : Souris
Un ordinateur est essentiellement composé d’une carte mère, c’est un circuit imprimé, qui supporte et relie tous les composants entre eux. On a le processeur – le coeur de notre ordinateur – qui est au centre de la carte mère.
Puis il y a la mémoire vive, la RAM, c’est une mémoire rapide qu’utilisent les logiciel quand l’ordinateur est allumé.
Il y a ensuite toute une série de connecteurs pour ajouter des cartes d’extension (Carte Graphique, Carte Son, Carte réseau) et pour connecter des périphériques. (clavier, écran et souris)

Enfin, il y a des connecteurs pour relier les différents supports mémoire qui conservent l’information quand l’ordinateur est éteint, il s’agit des disques dur et SSD. (Lecteur/graveur DVD)
Pour que tout fonctionne, il nous faut de l’énergie. Un ordinateur comporte donc toujours une alimentation électrique.
Pour mémoriser des informations, comme la langue du clavier, et l’heure, quand l’ordinateur est éteint, un ordinateur comporte aussi une pile électrique qui alimente une mémoire.
Périphériques et connecteurs
Le rôle d’un ordinateur est de traiter de l’information, mais d’où vient cette information ? Sous quelle forme le résultat du traitement de l’information est présenté ?
Un ordinateur communique souvent avec l’extérieur. Il va capter des données sur un périphérique, puis les traites et retourne le résultat sur un autre périphérique.
Les périphériques d’entrée – sortie, les plus courants sont le clavier et l’écran, au point qu’ils sont quasi toujours intégrés. Par le passé, on a vu dans la partie historique, qu’avant la généralisation des écrans, l’imprimante était le moyen courant pour afficher les données sortantes.
Exercice: faites une liste de périphériques courants.
Liste de périphériques d’entrée sortie
Voici une liste non exhaustive de périphériques d’entrée et sortie pour un ordinateur.
- Écran
- Clavier
- Souris
- Disque dur – SSD externe (pour sauvegarde par exemple)
- Imprimante
- Vidéoprojecteur (beamer)
- Clé USB
- Casque audio
- Scanner
- Tablette graphique – Tablette Wacom
- Lecteur DVD
- Webcam
- Microphone
- Carte SD et/ou son lecteur
- Baladeur mp3 – iPod
- enregistreur audio – dictaphone
- Appareil photo numérique
- Lecteur de carte NFC
- Manette de jeu
- Modem
- Switch réseau
- Casque de réalité virtuelle
- liseuse de bouquins électroniques
- smartphone ? est-ce vraiment qu’un périphérique ?
Exercice: quels sont les composants de VOTRE ordinateur ?
Connaissez vous une manière/commande pour faire la liste des composants de votre ordinateur ?
Indiquez combien de mémoire RAM dispose votre ordinateur ?
Avez vous un SSD ? Un disque dur ? de quelle taille ?
Quelle est le nom de la carte wifi ?
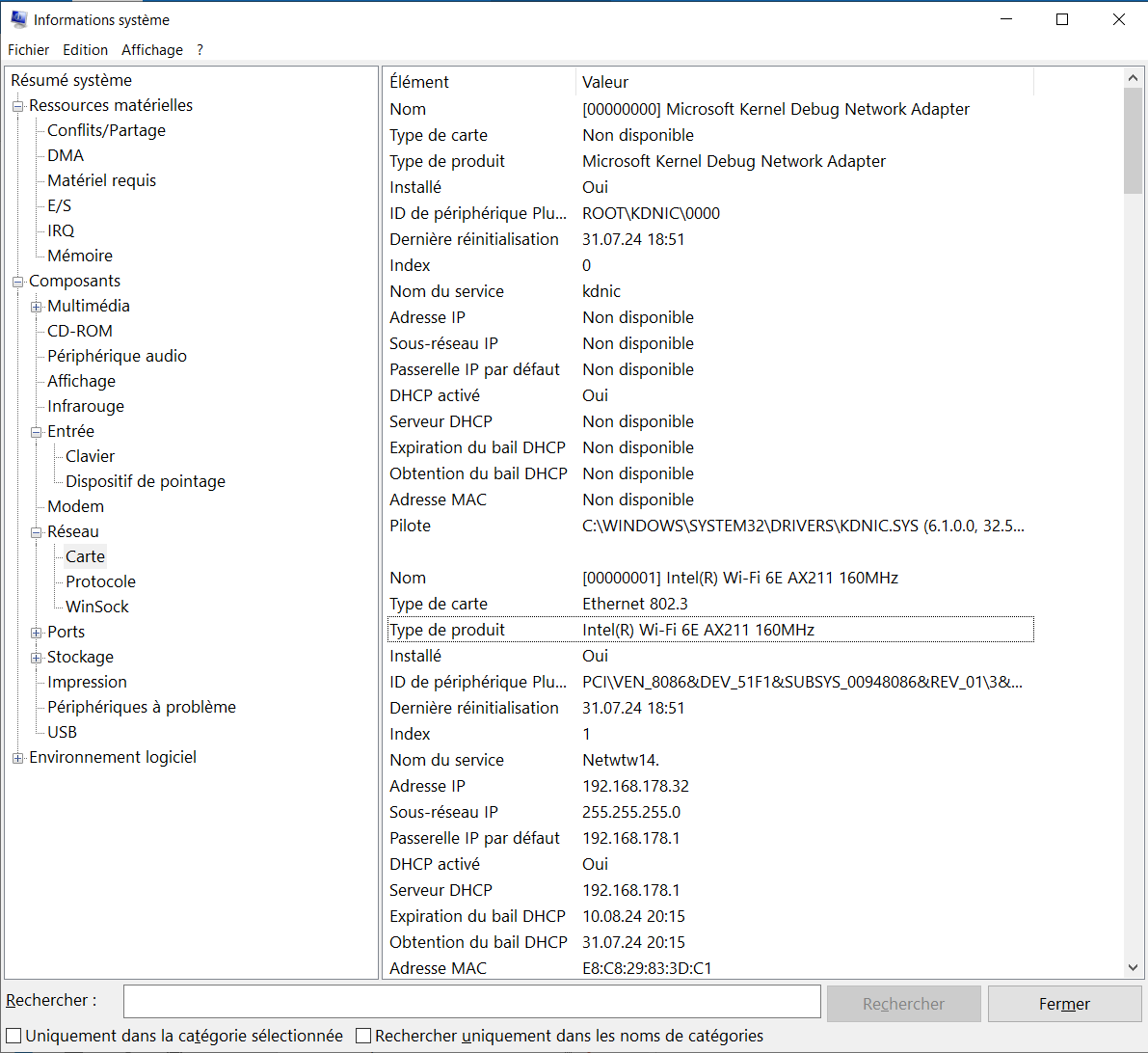
Comment afficher les informations système…
Sur Windows, pour afficher les informations systèmes, on peut appuyer sur le raccourcis clavier:
[Windows] + R Ce qui ouvre une fenêtre pour lancer un programme.
Taper: msinfo32 et confirmer.
Une fenêtre apparait avec les informations système.
Sur MacOS:
Dans le dossier utilitaires du dossier applications, il y a une application nommée: Informations système.app
Voici un raccourci clavier pour se rendre dans le dossier utilitaires:
[Command] + [Shift] + u
Dans le menu pomme il y a déjà « à propos de ce mac » qui permet d’avoir la base des infos systèmes, et le détail en cliquant sur « en savoir plus… » et encore une fois « réglages systèmes »…
Sur Linux:
Sur Ubuntu avec l’utilitaire graphique Hardinfo…
En ligne de commande:
Plusieurs commandes possibles…
sudo lshw -shortTout ces périphériques sont reliés à l’ordinateur via des connecteurs. Voici une liste de connecteurs.


- mini-Jack
- VGA
- HDMI
- Display Port
- USB 3.0
- USB type c – Thunderbolt 3
- port COM – port série DB9 – port console (RS-232)
- RJ45
- Bluetooth
- Wifi
Dans la jungle des connecteurs, l’important c’est de reconnaitre les familles de connecteurs. Est-ce que c’est un connecteur pour faire passer du son ? de l’image ? des données ? une alimentation électrique ? tout ? En analogique ou en numérique ?
Puis l’important c’est de connaitre les ordre de grandeur des débits de données possibles. Qu’est-ce qui est le plus rapide ?
Exercice: reliez des périphériques courants sur un ordinateurs en utilisant les bons connecteurs en tenant compte des débits.
- Allez faire un tour sur une boutique en ligne….
- Choisissez 3 périphériques (ayez un peu de créativité et d’imagination !)
- Créez un petit « mode d’emploi » comment les brancher sur votre ordinateur personnel et sur celui du labo.
Exercice: classez les moyens de connexion par débit
Classez les moyens de communications suivants par ordre du plus lent au plus rapide (notez le débit):
- USB « classique » couleur noir
- Port COM
- Ethernet 1000BASE-T
- Bluetooth 5
- SATAIII
- USB avec un connecteur type C
- Wifi 5 (802.11ac)
Réponses… ou aide pour les trouver…
Évaluation de la partie matériel
Première note pour ce module, créer un petit rapport qui décrit les caractéristiques matérielle de votre propre ordinateur personnel.
- modèle d’ordinateur
- OS
- processeur
- mémoire
- réseaux
- périphériques
- etc….
Voici les critères d’évaluation de ce petit rapport….
Logiciel
Allez on se le répète encore une fois, un ordinateur c’est une machine universelle, programmable.
Un ordinateur capte des informations, via des périphériques d’entrée, puis traite l’information et donne une réponse sur un périphérique de sortie.
Nous avons vu plus haut la partie matérielle de cette machine, le matériel, aussi nommé hardware en anglais.
Nous allons voir maintenant la partie immatérielle de cette machine, le logiciel, le software, en anglais.
C’est du mot software que vient le suffixe « soft » qu’on trouve à la fin du nom de Microsoft par exemple.
Si notre ordinateur est une machine programmable, le logiciel est ce programme. C’est un synonyme.
Avec le même matériel, on peut « faire tourner » une infinité de programmes différents pour résoudre une infinité de problème différents.
Le logiciel est enregistré dans une mémoire. C’est une suite d’instruction qui permet de piloter le matériel via un jeu d’instruction.
Généralement un logiciel est basé sur un algorithme.
Algorithme
Le mot algorithme est devenu courant dans les médias ces dernières années, mais sans vraiment que le grand public sache la définition exacte.
L’algorithme, c’est LA valeur ajoutée, l’or, le pétrole du XXIème siècle. C’est souvent ainsi que les médias en parlent quand les GAFAM, s’approprient les algorithmes pour assurer leur domination économique.
En fait le mot algorithme vient du nom du mathématicien persan Al-Khwârizmî qui a vécu entre 780 et 850, principalement à Bagdad. C’est lui a créée plein d’algorithmes ! … et accessoirement qui a diffusée les chiffres indo-arabe que nous utilisons de nos jours.
Voici la définition d’un algorithme:
Un algorithme est une suite finie et non ambiguë d’instructions et d’opérations permettant de résoudre une classe de problèmes.
Ça parait très pompeux ainsi, mais c’est très simple.
En fait, un algorithme, c’est tout simplement une recette de cuisine.
Prenons un exemple avec une métaphore.
Mon problème: réaliser un cake à la banane.
J’ai du matériel à disposition, des outils, mais aussi des ingrédients en entrées.
- 60g de sucre
- 60g d’huile de tournesol
- 200g de farine.
- 1 sachet de poudre à lever
- 1 pincée de sel
- 4 bananes
J’ai bien toutes ces ressources, mais ça ne me donne pas un cake à la banane. Il me manque la recette du cake à la banane.
La recette c’est l’algorithme pour résoudre mon problème. C’est une suite d’instructions finie, non ambiguë. Il faut que ce soir clair à chaque étape.
C’est quoi une pincée ? Une cuillère ? à café ou à soupe ? La banane entière ou pelée ? (ça peut donner un résultat différent !)
- préchauffer le four à 180°C
- mélanger le sucre et l’huile jusqu’à obtenir un mélange homogène
- écraser les bananes dans un récipient séparé
- incorporer les bananes écrasées au mélange
- ajouter la farine, la poudre à lever et le sel
- mélanger le tout
- verser la préparation dans un moule à cake
- cuire le cake pendant 45 min à 180°C

Attention il y a un bug dans la recette… une action non mentionnée… un pur ordinateur risquerai de faire un cake pas trop ragoûtant.. qui arrivera à trouver ce « bug », cette instruction manquante ?
La recette ci-dessus nous révèle que des instructions comportent des verbes d’action, en gras, et des sujets en italique. C’est une action que l’on effectue sur des éléments dans certaines conditions.
C’est exactement ainsi que fonctionne un ordinateur.
Un microprocesseur comprend un certain nombre de verbe, des instructions et il est capable de les appliquer à des données disponibles dans des registres ou des entrées sorties quand on lui donne l’adresse mémoire.

Voici un exemple d’assembleur utilisée sur l’Apple II.
Dans la colonne de gauche, on voit les adresses mémoire du programme. Puis le programme assembleur en hexadécimal, et l’équivalent humain (code à 3 lettres) de l’instruction avec la valeur sur laquelle l’instruction agit. On parle d’opérande. (ex:une adresse mémoire, une valeur fixe, un nom de registre, une adresse d’entrée sortie, etc..)
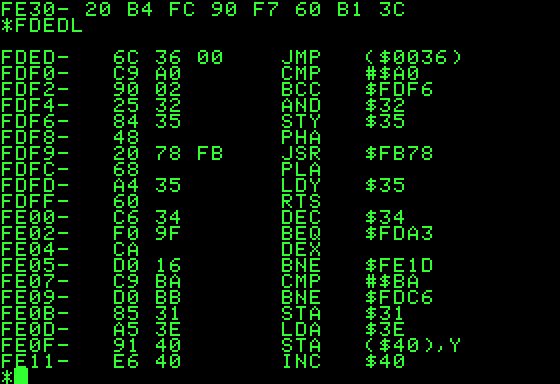
L’Apple II utilise une processeur MOS 6502 avec une architecture à 8 bits.
Exercice: l’aspirateur automatique !
Voici un exercice pour expérimenter ce qu’est un algorithme.
Ecrivez un algorithme qui permet de faire fonctionner un aspirateur automatique qui connait les instructions suivantes:
- avancer
- reculer
- stop
- tourner d’un angle de x° (dans le sens horaire)
- obtenir la distance par rapport à un objet devant lui.
L’aspirateur est rond. Il a deux roues motrices. Une de chaque côté. (et des petites stabilisatrices devant et derrière pour ne pas qu’il tombe.)
Il a un capteur qui lui permet de connaitre la distance à laquelle il se trouve d’un objet devant lui…. mais attention dans quelle unité de mesure il mesure ?? En Pouce ? en mètre ? en pied ?
On considère que l’aspirateur a un bouton d’allumage général manuel qui enclenche directement l’aspiration. Donc pas de programmation possible pour le démarrage et pour l’aspiration.
Voici un peu d’inspiration (à défaut d’aspiration) pour observer comment fonctionnent ce genre d’aspirateurs…

OS – Système d’exploitation
Alors une fois que nous avons un bon matériel et un logiciel, c’est bon, nous avons un ordinateur fonctionnel !
Alors oui, mais… C’est pas tout à fait ce que l’on a l’habitude actuellement.
Historiquement c’est vrai. J’ai un problème à résoudre, je programme ma machine pour résoudre ce problème.
Mais c’est fastidieux de devoir reprogrammer la machine à chaque exécution d’un programme.
Ce n’est pas très pratique de n’avoir qu’une seule application à la fois. Ce n’est pas très pratique de devoir gérer la gestion de la mémoire et d’autres tâche bas niveau dans mon programme. Si mon écran change je dois réécrire mon programme ?
C’est là qu’intervient le système d’exploitation. OS, Operating System.
Un système d’exploitation est un logiciel d’un genre particulier. C’est un logiciel qui a pour but de gérer la machine et ses périphériques de façon transparente pour le programme de haut niveau.
Les systèmes d’exploitation les plus répandus (sur smartphone et ordinateur de bureau confondus) sont:
- Android (40%)
- Windows (30%)
- iOS (17%)
- macOS
- Plein de distribution de Linux..
Pour comprendre le rôle d’un système d’exploitation, on peut prendre la métaphore du corps humain. Je n’ai pas besoin de penser consciemment à respirer, à cligner des yeux ou à faire battre mon coeur. Ma digestion est régulée de façon autonome.
Nous avons tous un système nerveux autonome qui gère nos processus physiologiques vitaux de façon transparente.
Par contre si je veux fermer les yeux ou prendre une grande respiration, je peux consciemment piloter ces organes. Par ma volonté consciente, je peux bouger mes bras, mes jambes, saisir des objets et les utiliser.
Un système d’exploitation est conçu en plusieurs couches. Au centre il y a le noyau, le kernel, qui est un peu à l’image de notre système nerveux autonome qui travaille sans en avoir conscience.
Puis ce noyau est entouré d’un environnement, des bibliothèques des logiciels qui permettent d’utiliser l’ordinateur, ainsi que de pilotes (drivers) qui permettent de reconnaitre et gérer les périphériques.
Noyau – Kernel
Voici les principaux domaines que gère le noyaux d’un système d’exploitation.
- système (composants, USB…)
- processeur
- mémoire de travail
- mémoire de stockage
- réseau
- Interface utilisateur
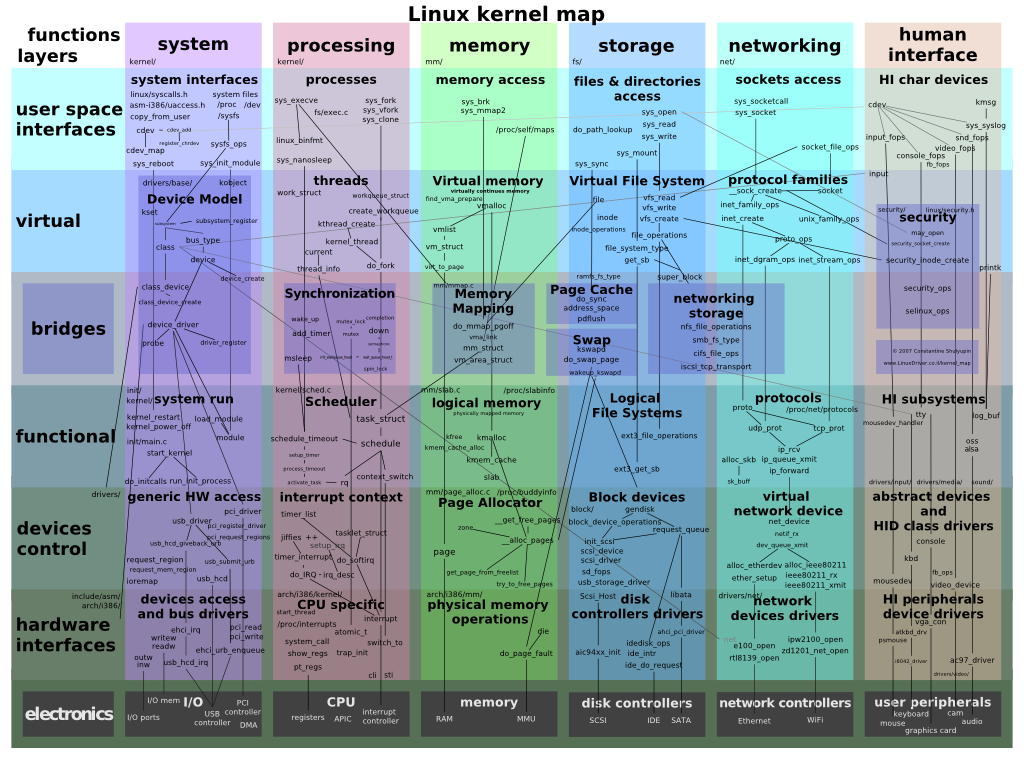
L’image ci-dessus nous montre les 6 domaines principaux et les couches du noyau Linux. C’est le noyaux le plus répandu, vu que Android utilise le noyau Linux.
Distribution
Dans le monde du logiciel libre on voit bien la différence entre un noyau et la distribution d’un système d’exploitation.
Dans le monde Apple ou le monde Microsoft, tout est tellement mis dans le même paquet que l’on ne distingue par bien la différence.
Voici un extrait de la chronologie des distributions de Linux.

Cet « arbre généalogique » est tellement grand que j’en ai fait un extrait avec la famille Debian qui est très connue, dont son issu par exemple Ubuntu et Raspeberry Pi OS.
L’arbre généalogique complet est visible par ici…
Chaque distribution contient le même noyau linux (Kernel), mais ce dernier est enrobé dans un environnement différent, une interface utilisateur différente, un set d’applications différents, etc….
Abstraction matérielle et logicielle de base
Le système d’exploitation est un logiciel qui fourni une abstraction matérielle. Il fourni une manière de communiquer standard avec un périphérique, une logique d’interface graphique, une gestion du réseau standard.
Ainsi un programmeur d’application de haut niveau peut directement utiliser les bibliothèques logicielles fournies par le système d’exploitation. Il se concentre sur la résolution de son propre problème. Ainsi le même programme peut fonctionner sur plusieurs machine différente. C’est le système d’exploitation qui va s’assurer de faire le lien entre le programme et le matériel.
Le système d’exploitation peut aussi nous faire croire que l’ordinateur sait faire plusieurs choses en même temps. (système temps partagé)
Le système d’exploitation gère l’accès au processeur. L’ordonnanceur découpe les tâches en petits morceaux pour les envoyer au processeur.
Ainsi je peux taper un texte en même temps que j’écoute de la musique, que je sauvegarde mes photos dans un nuage et que je reçois des e-mails.

Applications
Les applications sont des logiciels, des programmes, tout comme le système d’exploitation. Mais l’application est logiciel de haut niveau dédié à résoudre des tâches dans des domaines particuliers.
Voici quelques exemples d’applications:
- Photoshop est une application de retouche photo
- Visio une application de dessin de schéma vectoriel
- Wireshark un analyseur réseau
- VLC un lecteur de vidéo
Où se procurer des applications ?
Support physique
Historiquement le créateur d’un logiciel le distribue aussi. D’abord sur un support mémoire physique, comme un CD ou un DVD. Mais cette époque est révolue.
Téléchargement d’une image disque
Puis est venue l’ère du téléchargement sur un site web.
Il y a plusieurs formes de fichiers.
- l’image disque (qui était vendue sur support physiqu) .iso
- pour Windows les applications on une extension .exe
- sur Mac les applications sont distribuée sur une image .dmg
Attention à bien vérifier que la source est la bonne !
Il y a plein de faux logiciels qui sont en fait des virus, des malwares, cheval de Troye, etc…
Pour vérifier la source, le concepteur du logiciel peut aussi fournir un hash, une sorte d’empreinte du logiciel. Chez soi on peut passer le logiciel dans la même moulinette qui fourni un hash et comparer les empreintes. Elle doit être identique.
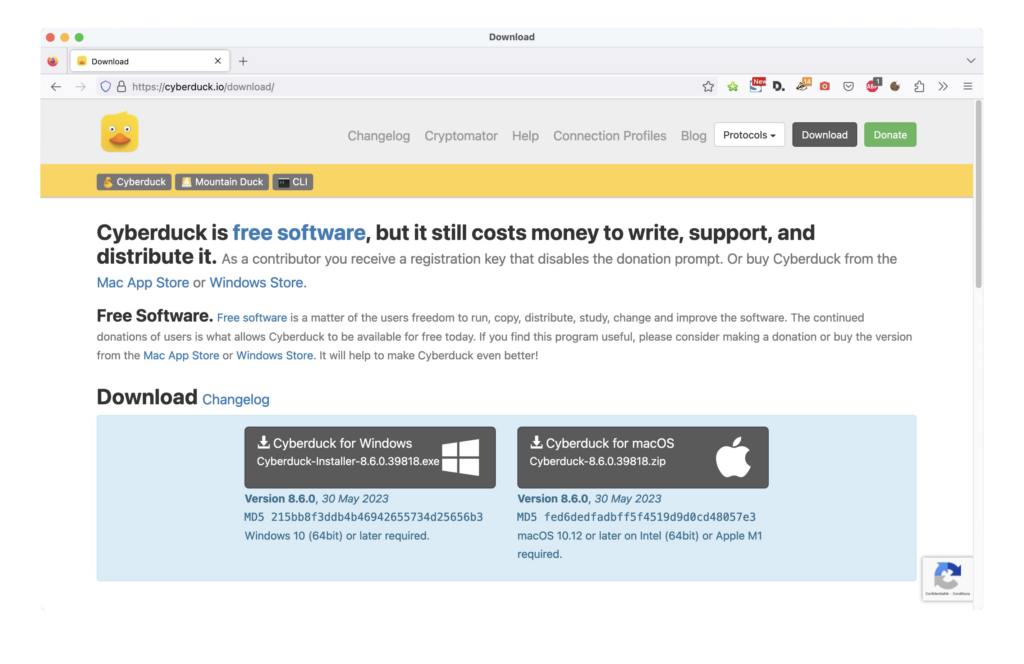
Voici un exemple de distribution en direct sur le site web du concepteur de logiciel. Ici l’excellent CyberDuck, logiciel suisse, de téléchargement SFTP et bien d’autres protocoles.
Ici on peut voir l’empreinte md5 qui est fournie pour vérifier chez soi qu’on a téléchargé le bon logiciel.
https://cyberduck.io/download/
Installation
Il peut y avoir juste l’application à installer dans le bon dossier ou encore un installeur qui va proposer les étapes d’installation et le faire soi même.
Il y a souvent deux types d’installation proposées:
- installation standard
- installation personnalisée
Attention à l’installation standard qui parfois installe beaucoup de logiciel inutiles.
C’est souvent le cas avec l’installation d’un pilote pour une imprimante/scanner qui installe aussi un logiciel de retouche photo même si on en a déjà un. Donc si je n’ai besoin que du pilote qui va permettre au système d’exploitation de gérer mon scanner ou mon imprimante, privilégier l’installation personnalisée.
Store
De plus en plus il y a des « store » qui fournissent des applications.
Dans le monde Linux, depuis longtemps il existe des gestionnaires de paquets qui permettent d’installer des applications et gérer leur dépendances.
Pour les geeks, la commande: apt install.. permet d’installer l’app désirée.
Il existe des versions graphiques, comme Aptitude.
Sur mac il y a Homebrew qui permet de gérer des paquets d’application.
Mise à jour
L’avantage du gestionnaire de paquet et du store, c’est qu’il vérifie l’origine du paquet et qu’il gère les mises à jour. Il notifie d’une mise à jour à faire.
Pourquoi faire une mise à jour ?
Il y a deux notions à distinguer (c’est subtile):
- update → la mise à jour → correction de bug, faille de sécurité
- upgrade → la mise à niveau → nouvelles fonctions
Il est bon de faire les mises à jour régulièrement, surtout les mises à jour de sécurité. En revanche, attention de ne pas faire de mise à jour trop rapidement.
Il peut toujours y avoir des défauts de jeunesse dans un logiciel. Il vaut mieux parfois attendre quelques jours pour savoir si d’autres personnes ont eu des soucis. (surtout si on a un gros projet à rendre, ne pas mettre à jour son logiciel le jour où il faut rendre le projet !!)
Donc c’est un subtile équilibre à trouver.
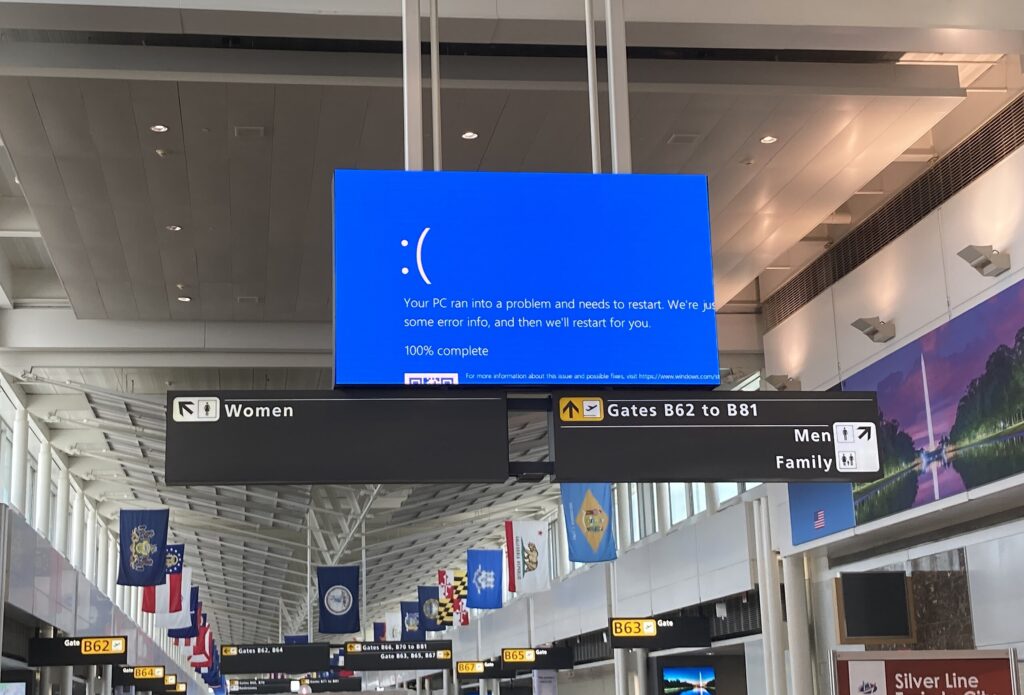
Pour illustrer les mises à jour hâtives. On peut évoquer la panne informatique mondiale du 19 juillet 2024 qui a bloqué de nombreux aéroports. Ceci à cause d’une mise à jour automatique du logiciel CrowdStrike qui s’est mal passée et empêchait Windows de redémarrer !
Licence logicielle
Un logiciel est juridiquement considéré comme une oeuvre du même genre qu’un livre ou une chanson. Le code source est un texte.
Le logiciel est donc soumis au droit d’auteur.
Par défaut un logiciel, n’est pas libre, il est la propriété intellectuelle de son auteur.
Cependant l’auteur peut donner des droits à l’utilisateur du logiciel.
Les droits sont distribués dans une licence. C’est un contrat qui donne des droits et des devoirs et qu’il faut accepter à chaque installation de logiciel.
Par exemple:
- utiliser le logiciel (dans un cadre prévu… Apple par exemple interdit l’utilisation de MacOs pour gérer des centrales nucléaires…)
- copier le logiciel
- améliorer le logiciel
- vendre le logiciel
- redistribuer le logiciel
- etc…
Le logiciel libre
Richard Stallmann est à l’origine du concept de logiciel libre distribué avec une licence « copyleft » (jeu de mot par opposition au « copyright »).
Pour qu’un logiciel soit libre, il doit garantir 4 libertés fondamentales:
- liberté d’utiliser le soft pour n’importe quel usage.
- liberté d’étudier le soft et de l’adapter à ses besoins.
- liberté de diffuser le soft et même de le revendre
- liberté de créer des remix et de les diffuser à la communauté

RMS a créé la licence GNU GPL. C’est une licence « virale ».
- Toute personne a le droit de piocher dans le code source sous licence GPL.
- Tout logiciel conçu avec du code issus du pot commun disponible sous licence GPL doit être intégralement mis à disposition sous licence GPL.
La licence GPL crée ainsi ce que l’on appelle un « bien commun« , c’est ni de la propriété privée, ni un bien public. C’est un bien à disposition d’une communauté qui a des droits et des devoirs.
Si j’utilise du code issus du pot commun, je dois mettre TOUT mon code dans le pot commun. Ainsi on évite un pillage des ressources publiques sans aucune contribution en retour.
Cette stratégie à fait largement grandir la communauté du logiciel libre.
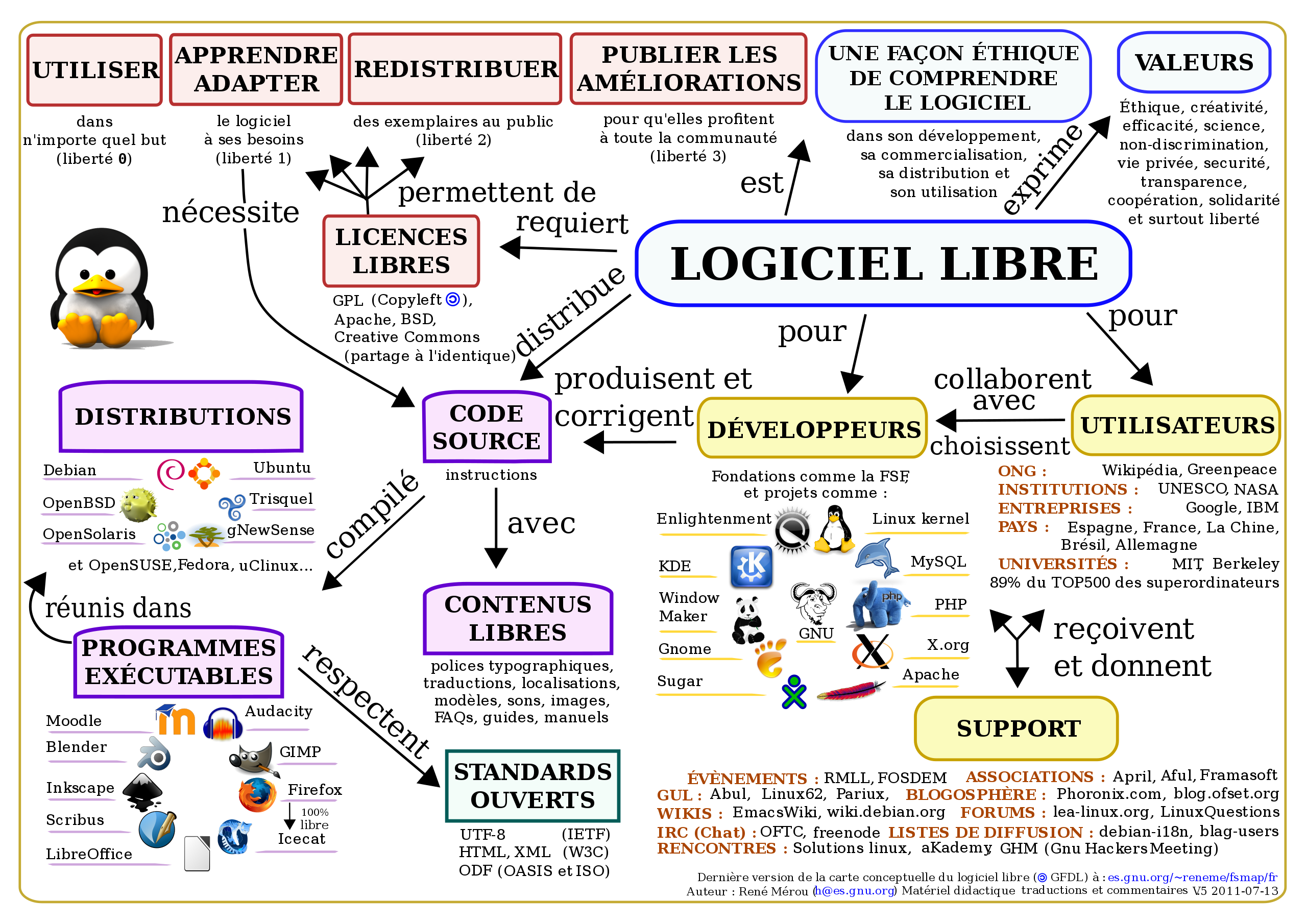
Attention, petite subtilité, il existe des logiciels qui sont Open Source, mais libre. C’est à dire que l’on a droit à obtenir le code source du logiciel. Mais les autres droits ne sont pas garanti. Les puristes font bien attention à ceci.
Tableau des types de licences et des droits
- freeware
- shareware
- logiciel libre
- logiciel propriétaire (privateur selon Stallman)
Voici une liste d’affirmations. Il y a une croix dans les colonnes des licences de logiciel pour lesquelles le droit en question s’applique.
| Droit | Freeware | Shareware | Propriétaire | libre |
|---|---|---|---|---|
| J’ai le droit d’utiliser le logiciel pour tous les contextes que je veux. | x | |||
| Je dois accepter la licence avant d’utiliser le logiciel. | x | x | x | x |
| Il est possible de devoir payer le créateur du logiciel. | x | x | x | |
| J’ai le droit d’observer le code source. | x | |||
| J’ai le droit d’adapter le logiciel à mes besoins. | x | |||
| J’ai le droit de diffuser le logiciel sur mon site web. | (x) | (x) | x |
Pour les freeware et shareware, la diffusion du logiciel n’est pas forcément explicitement autorisée, mais généralement les auteurs sont contents de voir leur création se diffuser.
Il est à noter qu’un logiciel libre, n’est pas forcément gratuit. En anglais, il y a une confusion, car le mot free utilisé pour free-software, signifie autant libre que gratuit !
Il y a des logiciels libres qui sont payants. C’est le cas de Cyberduck. Si l’on ne paie pas, il y a un message pour faire un don ou acheter une clé d’activation qui apparait à chaque fermeture du logiciel. Si l’on passe par le Mac App store ou le Windows store, cyberduck est payant dans tous les cas.
Licences Microsoft
Une licence est un contrat pour donner des droits et des devoirs à un utilisateurs par un concepteur de logiciel.
Comme vu ci-dessus, dans le monde du logiciel libre on tend à garantir des droits étendus. A contrario dans le monde propriétaire on tend à restreindre les droits des utilisateurs avec un jeu complexe de types de licences différentes afin de faire passer à la caisse les utilisateurs.
La motivation financière complexifie le choix des logiciels. C’est parfois la jungle pour s’y retrouver dans les différents types de licence qui existes et parfois les règles changent.
Voici dans les grandes lignes, les types de licences qui existent, on va prendre l’exemple de Microsoft, car c’est le plus tortueux:
- OEM → Original Equipement Manufacture → lié à l’achat d’une machine… et lié à la machine à l’infini. → autocollant sur la boite du PC.
- FPP → Full Packaged Product – autonome ou Retail. Pour installer 1 copie du logiciel sur 1 poste (retail = un poste, mais n’importe lequel)
- Mise à jour → seulement si on a déjà le soft. C’est un rabais pour une nouvelle version.
- Volume → Comme FPP, mais pour une masse de machine. Pratique pour les grandes organisations.
- Open Value → location, sous contrat d’utilisation.
- Numérique → nouvelle manière d’activer Windows depuis la version 10. Il n’y a plus de clé de licence à entrer, mais une activation par Internet qui prend une empreinte de sa configuration matérielle pour identifier la machine.
- Nombre d’utilisateurs → pour le bureau à distance RDS, il faut acheter une licence en fonction du nombre d’utilisateur. On retrouve ce principe dans les licences pour l’utilisation du PBX 3CX dans le domaine de la VOIP.
Voici une page pour tout savoir sur les licences Microsoft….
Voici un guide de Microsoft pour choisir la bonne licence adaptée à ses besoins:
Licence Creatives Commons
Par défaut toute oeuvre est placée dans le mode juridique « tout droit réservé » pour son auteur.
Donc si vous piquez une image, un texte, un code, trouvé sur Internet, vous n’avez aucun droit dessus. Le créateur/propriétaire à tous les droits. Donc si vous voulez utiliser une oeuvre, il faut impérativement demander la permission à l’auteur. Ce dernier peut octroyer certains droit dans une licence selon les conditions qu’il désire.
Contacter l’auteur est très contraignant pour obtenir un droit, et rien n’est garanti. A la vitesse actuelle des interactions, je n’ai pas le temps de contacter un auteur et d’attendre sa réponse pour l’utilisation d’une image juste pour ma publication sur facebook qui sera déjà oubliée demain…
Pour résoudre ce genre de problème. Le juriste Lawrence Lessig a créé l’initiative Creatives Commons qui propose des licences utilisateurs standards que l’on peut associer à son contenu. Ainsi pas besoin d’être juriste pour créer une licence et l’on peut en avance accorder certains droit aux oeuvres que l’on publie sur le web.
Il suffit de piocher dans les 4 restrictions que l’on souhaite et de créer sa licence adaptée:
- Attribution : signature de l’auteur initial (sigle : BY)
- Non Commercial : interdiction de tirer un profit commercial de l’œuvre sans autorisation de l’auteur (sigle : NC)
- No derivative works : impossibilité d’intégrer tout ou partie dans une œuvre composite ; l’échantillonnage (sampling), par exemple, devenant impossible (sigle : ND)
- Share alike : partage de l’œuvre, avec obligation de rediffuser selon la même licence ou une licence similaire (sigle : SA)
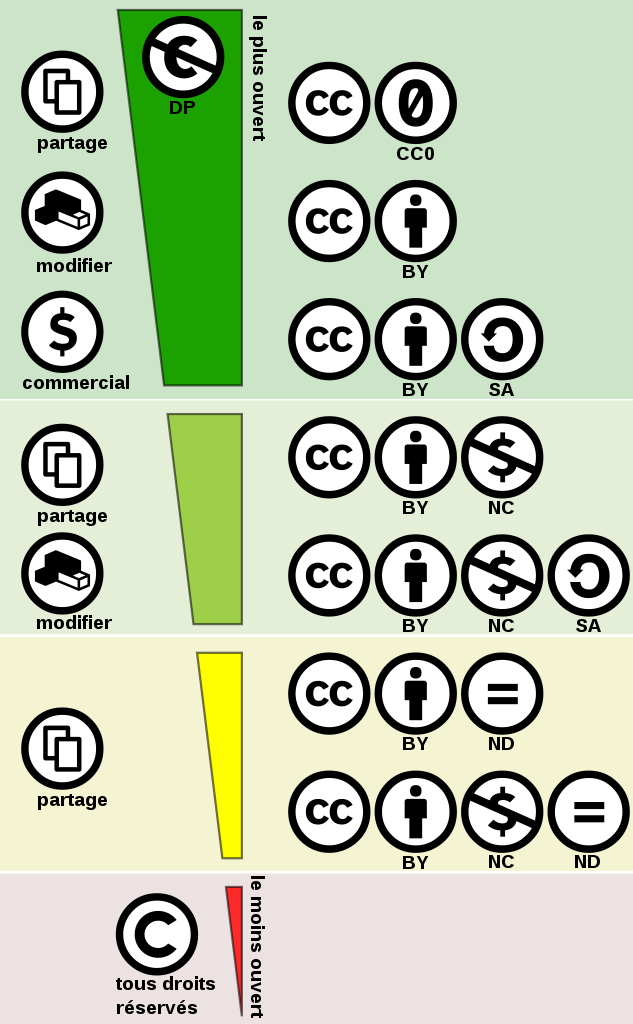
La licence la plus courante est la CC-BY-SA, c’est la licence qui est utilisée sur wikipedia.
Cette licence autorise à :
- utiliser, copier, partager et diffuser le contenu.
- adapter, remixer, intégrer le contenu, même dans une utilisation commerciale.
Ceci sous la conditions de:
- citer l’auteur (BY) avec un lien par exemple
- en cas de remix, partager l’oeuvre dérivée sous la même licence. (SA)
Il y a de nombreuses plateformes d’hébergement de contenu qui utilise ces licences. (youtube, wikipedia, )
Pour en savoir plus sur les entraves du mode de fonctionnement actuel du droit d’auteur et comme l’industrie arrive à modifier le droit pour protéger ses profit (par exemple avec la loi Mickey), voici le livre: « culture libre » de Lawrence Lessig:
Cloud-computing – Info-nuagique
De plus en plus les applications ne sont plus directement installées sur une machine en local, mais sont accessible à distance, généralement via un navigateur web. On parle de Software As a Service.
C’est l’informatique dans le nuage.
Voici la page dédiée au cours complet sur l’informatique dans le nuage, le cloud…

Sécurité informatique
Tout devient de plus en plus informatisé, c’est très pratique pour les possibilités de gestion qui sont offerte, mais si l’on arrive à gérer une infrastructure à distance, si elle est mal sécurisée, d’autres y arriverons aussi !
Voici un tweet d’un groupe de pirate qui montre des captures d’écran de l’interface de gestion du réseau d’eau de Londres.
Par éthique, ils n’ont rien touché, mais dénoncent la mauvaise sécurité de cette infrastructure très critique.
La grande tendance actuelle est aux Randsomware, soit littéralement les logiciels de rançon.
Le principe est simple. Un groupe de pirate s’introduit dans le réseau informatique d’une organisation. Il installe un logiciel qui va chiffrer toutes les données. Tout devient illisible pour la victime.
Elle peut « se libérer » en payant une rançon qui correspond généralement à son chiffre d’affaire / Budget. Si elle paye, elle reçoit la clé de déchiffrage et tout est fini.
Si la victime refuse de payer, elle doit retrouver ses données par elle même, ce qui peut jouer avec un bon système de sauvegarde. (mais c’est là qu’on découvre en général que sa politique de sauvegarde n’est pas parfaite !)
Mais ce n’est pas tout. Elle s’expose au risque que les pirates publient sur leur site sur le Darkweb toutes les données collectées. Il peut y avoir des données confidentielles !
Un des cryptolocker les plus connus est LockBit, ce groupe a même fait une campagne de pub tout à fait particulière en offrant 1000$ à toute personne qui se fait tatouer leur logo !!!
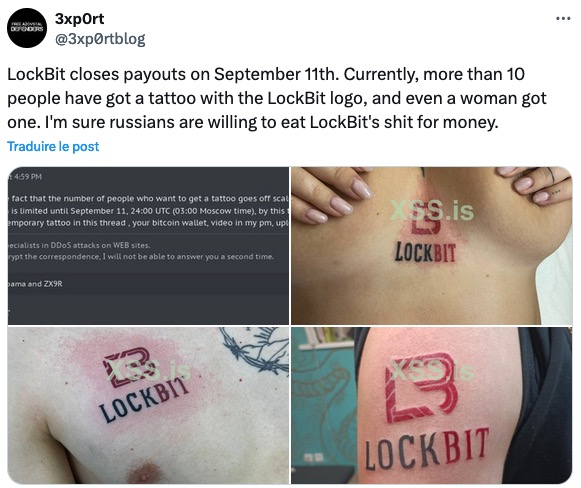
Ce groupe a notamment piraté l’Université de Neuchâtel, et des cabinets médicaux de la région en début de l’année 2022.
Les risques d’une sécurité informatique défaillante
Les principaux risques:
- indisponibilité des services
- perte (altération) de données
- fuite de données
Donc en conséquence:
- → perte d’image/confiance
- → perte financière
- → cessation activité
Qu’est-ce que la sécurité informatique ?
Il y a 4 points principaux à prendre en compte:
- intégrité → modification maitrisée → que par personnes autorisée, selon un processus défini.
- Confidentialité → liste de distribution maitrisée → accessible que aux personnes autorisées.
- Disponibilité → mise à disposition contrôlée → accessible à un endroit et une heure prévue.
- (Traçabilité → enregistrement des traces) → enregistrement des traces de changement d’états.
Les 4 axes de la sécurité informatique
Il est nécessaire pour se protéger des risques de sécurité de définir une politique de sécurité.
Voici Les 4 axes principaux pour « la politique de sécurité »
- Logique → droits accès, sauvegarde, mise à jour, anti-virus, pare-feux
- Réseau → protection des canaux de communication interne et externe de l’organisation
- Physique → infrastructure, clé, salles, espace communs. Session ordi ouvertes
- Humaine → le soucis est entre la chaise et le clavier ! → social hacking, fishing
Voici la politique de sécurité du CPNE définie sur l’extranet.
Fishing – Hameçonnage
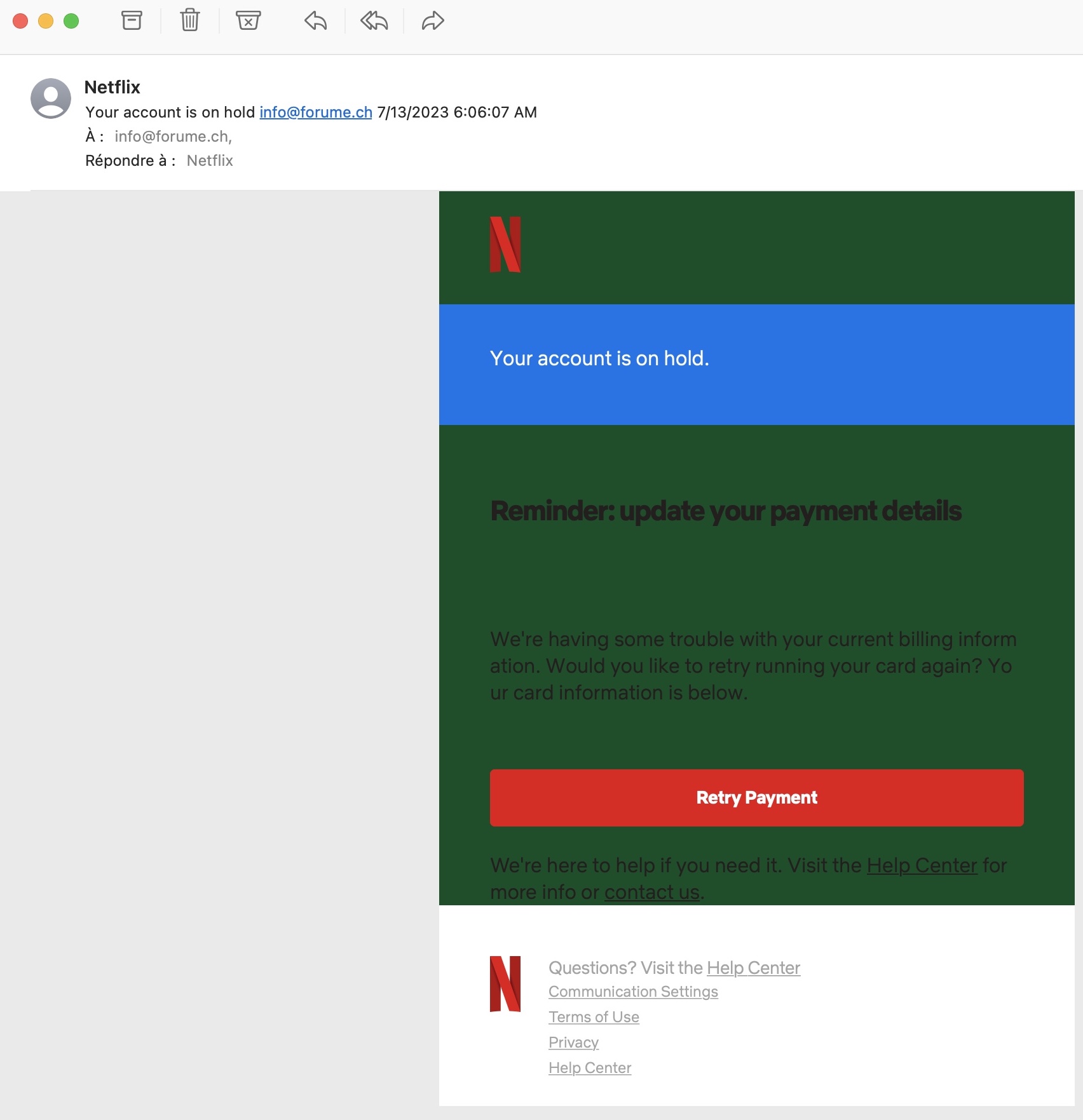
Une des menaces les plus courantes, c’est le fishing, littéralement la pêche… (au pigeon). En français on utilise le terme de Hameçonnage.
Ce sont des e-mail frauduleux, envoyés pour que l’on clique sur un lien. Le pirate espère ainsi récupérer des données personnelles et surtout des identifiants permettant d’avoir accès à un compte bancaire ou une carte de crédit.

La plupart du temps le e-mail est très souvent plausible.
C’est une copie d‘un service de livraison qui demande de payer pour la douane. C’est un service de cloud qui vous propose une facture, Apple iCloud, Netflix, etc..
C’est une banque qui vous demande de changer votre mot de passe. Attention aucune banque ne procède ainsi !!!
Voici quelques exemples de fhishing:

Comment détecter un message frauduleux ?
La meilleure technique est d’observer l’url. L’adresse du site web pointé n’est généralement pas le bon !
C’est souvent l’adresse d’une site web piraté par le pirate qui héberge à son insu un faux site web, ou un site fait sur un service de lettre de nouvelle.
Il faut bien lire les différentes partie de l’url, parfois c’est subtil, le nom du service piraté est mis dans un nom d’hôte, mais le nom de domaine est faux.
Il faut observer autant l’adresse de l’expéditeur, que l’adresse du lien. Cette dernière peut se voir au survol du lien. Mais ce survol n’est pas possible avec un smartphone !

Exercice:
- Comment identifier qu’un e-mail n’est pas du hameçonnage (fishinng) ?
- Formation à la cybersécurité fournie par le canton de vaud eSUSI…..
- Qu’est-ce qu’un SPAM ?
- Comment choisir un bon mot de passe ?

Intro au Dark Web

Voici une introduction au dark web…. comment ça marche, ce qu’on y trouve, les fantasmes, et la réalité…
Protection des données et politique de confidentialité
Grâce à l’informatique de plus en plus de données sont échangées facilement. Souvent c’est très pratique, mais parfois on s’en passerait bien.
Face à des abus dans le domaine de la protection des données personnelles. La loi sur la protection des données a été mise à jour en Suisse.
Depuis le 1er septembre 2023, c’est la nouvelle LPD qui fait foi.
Depuis 2018, le RGPD européen a déjà bien mis en place des règles de protection des données.
Voici le site de l’administation fédérale à propos de la protection de données
Voici les modifications de cette nouvelle loi sur la protection des données en Suisse:
- Nouvelle LPD compatible RGPD mais avec l’esprit Suisse: plus simple! plus Bref, plus abstrait, neutre techniquement.
- Concerne uniquement les données des personnes privées. (plus les personnes morales comme avant! … donc même champ d’application que RGPD. Pour entreprise: secret commercial art 162 code pénal, et art 28 code civil: protection de la personnalité)
- art.5: Ajout des données génétiques et données biométriques aux données personnelles sensibles. (opinion, religion, philosophie, politique, syndicale, mesures sociales, génétique, biométrique, santé, sphère intime, origine raciale ou ethnique, poursuites, sanctions pénales ou administratives, aides sociales)
- art.7: Privacy by design et privacy by default.
- → case à cocher de newsletter non cochée par défaut !les softs doivent systématiquement prévoir que les données puissent être effacées ou anonymisées.
- seules les données absolument nécessaires doivent être collectées/traitées. → principe de proportion art.6, al.2 et art.13 de la constitution suisse.
- art.10: Une entreprise PEUT désigner un conseiller à la protection des données. C’est facultatif, (au contraire du RGPD)
- art.22: Etude d’impact à réaliser si:
- traitement à risque élevé pour la personnalité.
- traitement à risque élevé pour les droits fondamentaux. (art. 7 à 36 Constitution. )
- profilage à risque élevé.
- traitement à grande échelle de données sensibles. (opinion, religion, philosophie, politique, syndicale, mesures sociales, génétique, biométrique, santé, sphère intime, origine raciale ou ethnique, poursuites, sanctions pénales ou administratives, aides sociales)
- On peut éviter l’étude d’impact si:
- on se soumet à un code de conduite d’une association professionnelle. Qui lui a été validé par le PFPDT (Préposé fédéral à la protection des données et à la transparence). art.11
- on utilise un logiciel certifié. art 13
- art.12: Les entreprises de plus de 250 employés doivent tenir un registre des activités de traitement.
- art.16: Communication de données à l’étranger uniquement si la protection est adéquates. attention ⚠️ cloud !!
- → obligation d’indiquer le pays dans lequel les données sont envoyées pour traitement. (plus restrictif que le RGPD)
- A ce propos la confédération est prise à son propre jeu…. le choix de datacenter chinois et états-uniens pour le cloud de la confédération n’est probablement pas compatible avec la nouvelle loi !! Une clarification juridique et en cours… → https://www.letemps.ch/economie/cyber/un-citoyen-pourrait-faire-derailler-projet-cloud-federal-110-millions-francs
- art.19: Obligation d’informer préalablement pour TOUTE collecte de données la personne concernées. (jusqu’ici ce n’était que pour les données sensibles)
- → créer une page de politique de confidentialité qui définit:l’identité du responsable de traitement (nom de l’organisation)ses coordonnées de contact destinataire(s) des données personnelles finalité de l’usage des données le pays dans lequel les données sont envoyées (si un cloud par exemple) → Plus stricte que RGPD.
- Dans le RGPD, il y aussi d’autres infos comme: la durée de conservation des données.
- art.25: La personne concernée a le droit d’accéder aux données qui sont collectées sur elle. (dans les 30j)
- les données à fournir sont les mêmes qu’à l’art 19.. +les données elles même évidement !!la durée de conservation des données (ou les critères qui fixent la durée. Ex: « 3 mois depuis la collecte »)
- l’origine des données si elles ne viennent pas directement la personne. (un automatisme… le log d’IP ?)
- art.28: Le format des données doit être un format électronique couramment utilisé. (un dump sql suffit)
- art.49. al.1: Le PFPDT (Préposé fédéral à la protection des données et à la transparence) doit ouvrir d’office une enquête si il y une infraction à la LPD.
- art. 51, al.1: Le PFPDT peut ordonner, la modification, suspension ou cessation d’un traitement de données, ainsi que l’effacement et destruction de données personnelle.
- art.60: Seules les violations intentionnelles de la LPD seront sanctionnées par l’amende. (jusqu’à CHF 250 000.-), pas les négligences.
- l’insoumission à une décision du PFPDT est poursuivie d’office.
- le non respect du devoir d’informer, de renseigner et d’annoncer sont punis sur plainte uniquement.
Données personnelles sensibles
Cette loi concerne les données personnelles, c’est quoi une donnée personnelle ?
C’est toutes les informations concernant une personne physique identifiée ou identifiable.
Par exemple une adresse IP, une date de naissance, un nom, sont des données personnelles.
Il y a une catégorie de données personnelles qui est jugées « sensible« . Il s’agit des données suivantes:
- les données sur les opinions ou les activités religieuses, philosophiques, politiques ou syndicales,
- les données sur la santé, la sphère intime ou l’origine raciale ou ethnique,
- les données génétiques,
- les données biométriques identifiant une personne physique de manière univoque,
- les données sur des poursuites ou sanctions pénales et administratives,
- les données sur des mesures d’aide sociale;
Exemple à propos des adresses IP:
→ IP et e-mail est une donnée personnelle, mais pas sensible.
Procès Logistep:
« Dans son arrêt du 08.09.2010, le Tribunal fédéral à Lausanne a admis que les adresses IP constituaient des données personnelles et relevaient, comme telles, de la loi sur la protection des données. Il a également considéré, à la majorité de ses membres, que les recherches effectuées secrètement par des entreprises privées afin de collecter des adresses IP étaient illicites, aucun motif suffisant ne justifiant une telle pratique. Le jugement fait interdiction immédiate à la société Logistep SA de collecter et de transmettre des données personnelles ; elle doit donc mettre fin à tout traitement de données dans le domaine du droit d’auteur. »
Il semble que depuis 2020, la collecte d’adresse ip est autorisé ? .. à creuser je ne trouve plus l’info.
Politique de confidentialité
Pour résumer les grands principes de cette nouvelles loi:
- principe de proportionnalité → ne collecter que ce qui est nécessaire.
- politique de confidentialité → Contrat: comment sont utilisées les données collectées, pour quel usage, par qui, dans quel pays.
- droit d’accès aux données → la personne concernée peut demander les données qui la concerne.
- Privacy by design → pas le droit de cocher la case « inscription à la lettre de nouvelle par défaut ». Le cas par défaut doit être le plus protecteur de la vie privée.
{kind=link}
{kind=link}
{kind=link}
La Politique de confidentialité est un contrat dans lequel on décrit tout, mais que personne ne lit complètement !!
Dans la nouvelle loi LPD, il doit y avoir:
- l’identité de l’organisation/personne qui gère les données
- les coordonnées de contact
- la finalité de la collecte des données. (à quoi ça sert ?)
- si il y a un sous traitant hors de Suisse, il faut indiquer le pays. C’est souvent le cas avec des services de statistiques ou d’hébergement dans un nuage.
C’est finalement très simple. Si il n’y avait que ça, on lirait certainement plus souvent l’intégralité de ces contrats.
Voici des exemples de politiques de confidentialités que des milliards de personnes signent les yeux fermés !

Politiques de confidentialité d’Instagram
Résumé simple de la version 2017 de la politique de confidentialité instagram:
« Vous êtes propriétaire des photos et des vidéos que vous publiez, mais nous sommes autorisés à les utiliser, et nous pouvons laisser les autres les utiliser aussi, partout dans le monde. […]
Nous pouvons conserver, utiliser et partager vos informations personnelles avec des entreprises liées à Instagram. Ces renseignements incluent votre nom, votre adresse électronique, votre école, votre lieu de résidence, vos photos, votre numéro de téléphone, vos préférences et aversions, vos destinations, vos amis, votre fréquence d’utilisation de l’application et tout autre renseignement personnel que nous trouvons, comme votre anniversaire et les personnes avec qui vous échangez, y compris dans les messages privés.”
Whatsapp….
En 2021, la mise à jour de la politique de confidentialité de Whatsapp a fait du bruit. Beaucoup d’utilisateurs sont partis sur Signal ou Telegram.
Mais quels sont les vrais changements ?
- partage des données avec la maison mère: meta (facebook).. mais en fait déjà depuis 2016 ! (rachat 2014) Mais en 2016 il y avait une case à cocher pour refuser le transfert, option qui a disparue pour les nouveaux comptes.
- ip
- no tel
- info de connexion, avec qui, quand.
- La nouveauté → service commercial, entreprise → la collecte de data est autorisés pour le entreprise qui font leur services clients sur whatsapp.
Il est à noter que contrairement à Facebook Messenger ou Instagram qui font partie du même groupe Meta, le contenu des messages de Whatsapp est chiffré de bout en bout. Donc théoriquement Meta n’a pas accès au contenu, mais uniquement aux méta-données de connexion, heures, avec qui, etc..
(sauf quand le message est « signalé » à des modérateurs.)
Infomaniak
Voici la politique de confidentialité d’infomaniak…
Cas d’un site de e-commerce en Suisse
Pour les sites de e-commerce en Suisse, il y a quelques règles de plus que pour une simple collecte des données.
Le KMU, le portail des PME de l’administration fédérale donne des informations sur sa page.
En bref:
- adresse de contact, postale et mail
- chemin de paiement clair
- politique de confidentialité
Cookie ?
Qu’en est il des fameux cookies ?

C’est quoi un cookie ? → Techniquement c’est un moyen de réaliser une session.
C’est la couche OSI 5, la couche de session.

Le protocole du web, HTTP est une protocole « amnésique » il fait le boulot, puis recommence avec une nouvelle requête. Mais il ne garde pas de mémoire d’une requête à une autre.
Ainsi si je veux créer un panier d’achat sur un magasin en ligne, et bien à chaque requête ça peut être un client différent. Je suis obligé de mettre en place un mécanisme qui va relier des requêtes entre elles. C’est la notion de session.
Comme HTTP ne dispose pas nativement de mécanisme de session, on a inventé le cookie !
C’est un petit fichier texte qui est enregistré dans le navigateur web. On y enregistre très peu d’information. Car ce fichier est envoyé à chaque requête! (une sorte de pièce jointe)
On enregistre les informations sous forme « clé=valeur ».
Très souvent on met la langue choisie par le visiteur. Ex:lang=fr
Là, c’est un cas simple. Mais très souvent on a besoin de beaucoup plus d’information. Ainsi on aura juste un numéro d’identification pour une base de données:
Ex:id=1618000691
« Veuillez accepter les cookies » .. miam oui !
Il y a beaucoup de fantasme sur la « dangerosité » du cookie. Il y a eu par le passé des failles de sécurité qui permettaient à un site web de demander les cookies d’une autre site. Ainsi un site pouvait voler des données. Mais il n’y a plus de faille depuis longtemps.
De plus voler la langue préférée d’un visiteur n’est pas si grave, ou voler un identifiant ne fourni pas les données si on a pas la base de données qui y corresponds !
Néanmoins des personnalités politiques se sont emparée de la psychose pour avancer leur carrières. « Je protège la population en créant un texte de loi ». La loi Européenne demande le Consentement pour accepter un cookie (puis aussi les tracker par empreinte)
Donc on voit des bannières de cookie fleurir sur tous les sites web. Si on suis la même logique, on devrait mettre de telle bannière à chaque fois qu’on envoie un SMS ou un message WhatsApp, car là, le protocole a aussi une Session !
Le paradoxe, c’est que techniquement il est très difficile de se souvenir du choix de l’utilisateur si il a coché la case qui dit qu’il accepte les cookies ou non. Donc on crée un cookie pour mémoriser ce choix !!!

Dois-je mettre une bannière de cookies sur mon site Internet?
Pour la Suisse, un coup d’œil à la loi sur les télécommunications (LTC) permet de répondre à cette question. L’art. 45c de la LTC stipule que:
«les données enregistrées sur des appareils appartenant à autrui ne peuvent être traitées par voie de télécommunication […] que lorsque l’utilisateur a été informé du traitement et de sa finalité et avisé qu’il a la possibilité de refuser ce traitement.».
Ainsi l’utilisation de cookies et d’autres technologies similaire est en principe autorisée en Suisse sans le consentement de l’utilisateur tant que celle-ci ou celui-ci n’exerce pas son droit de refus ou que le site Internet concerné utilise des méthodes qui ne génèrent pas de données personnelles.
Selon le droit suisse, il suffit de mettre les informations sur le traitement des données et le droit de refus à la disposition des utilisatrices et utilisateurs, ceci dans le texte de déclaration à propos de la protection des données exigé par la nouvelle LPD de 2023.
Ainsi il n’est pas nécessaire, en Suisse, d’afficher une bannière demandant d’accepter les Cookies.
Voici donc un avis de juriste que l’on peut trouver. Même si j’ai vu d’autres juriste qui recommandent tout de même de mettre une bannière à cookie, notamment pour répondre au droit européen, vu que l’on ne sait pas d’où viennent le visiteurs !
.. et pour terminer, ça donne faim de parler de Cookie.. Voici donc ma recette de Cookie en bocal à offir à Noël…
Tracking par « mouchards »
Un autre soucis sur la protection des données, c’est plutôt les régies publicitaires ou outils de statistiques (qui en fait sont les mêmes… Google AdSense couplé à Google analytics par exemple !)
Google analytics est présent sur un très grand nombre de site. Ainsi le cookie de Session est reconstitué d’un site à l’autre en fonction de détection de paramètres comme la taille d’écran, l’OS, l’IP source, le navigateur web, les plugins installés. Il semble que Google Analytics peut se baser sur une centaine de critères pour identifier un visiteur unique. Cette information peu être enregistrée dans un cookie. Mais elle peut tout aussi bien être reconstituée sur le moment. Donc le cookie n’est pas en cause.
Vous pouvez installer Privacy Badger, un plugin fait par l’EFF pour se protéger contre les trackers.
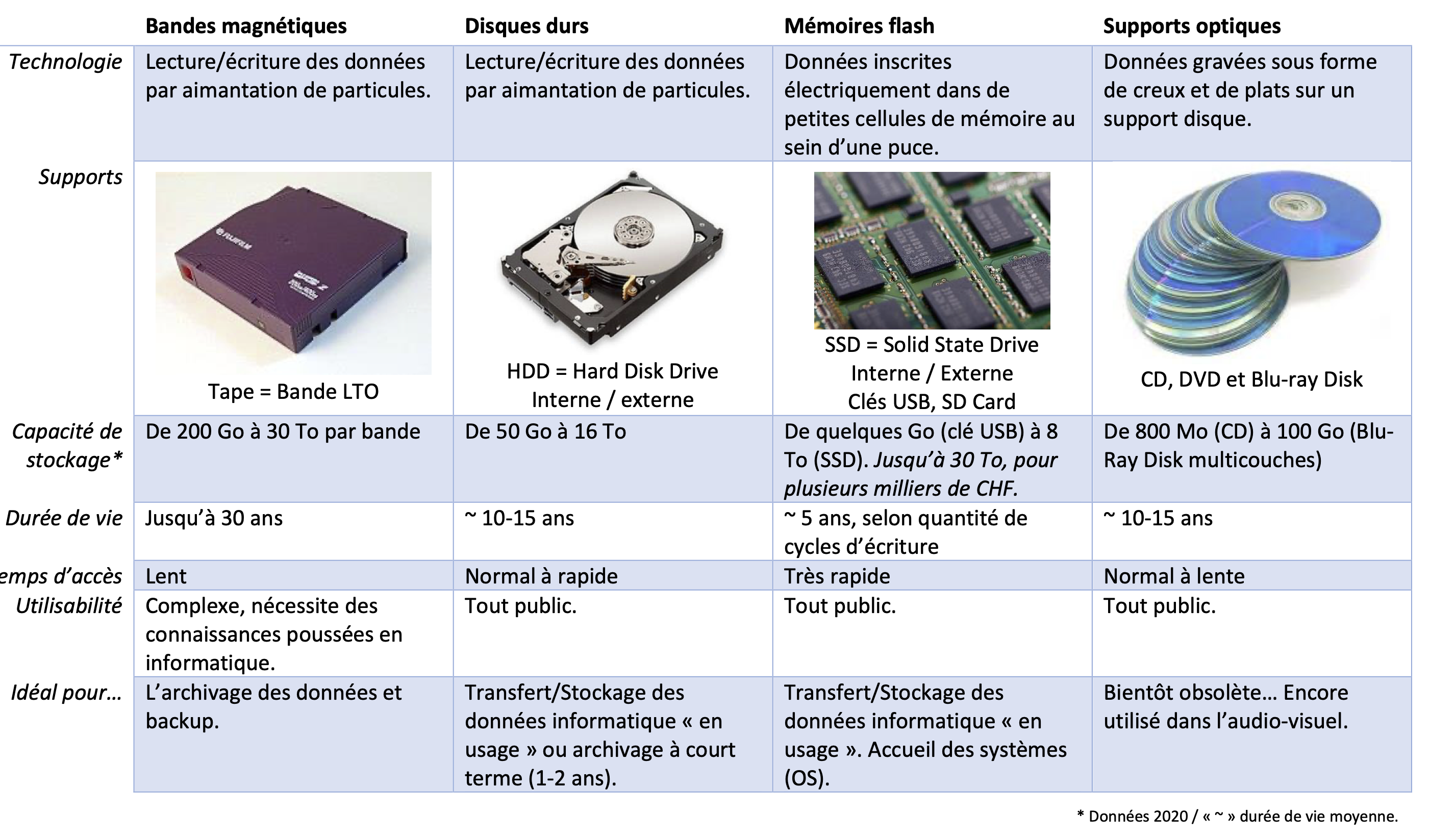
Sauvegarde des données
Quel et le but d’une sauvegarde ?
=> Faire une copie de sécurité des données à un temps T.
Le but n’est pas un archivage, n’est pas de libérer de la place. Mais bel et bien d’avoir une copie de ses données au cas où on en aurait besoin.
Principe du 3-2-1
Au moins 3 copies sur au moins 2 supports physiques différents et au moins une copie sur un autre lieu. (cloud ou chez sa grand mère)
Il existe une grande variété de support. Mais peu sont vraiment durables.
La sauvegarde dans le nuage est très abstraite. Il s’agit en fait de l’ordinateur de quelqu’un d’autre ! Il faut en accepter les risques.
Voici une photo rare de la visualisation du « nuage ». Ici ce sont des données qui partent en fumée dans l’incendie d’un datacenter d’OVH.

Penser à sauvegarder ses données est une tâche à faire avant un problème.
Il y a plusieurs manières de faire une sauvegarde données:
- un clone, une copie exacte des données
- une sauvegarde incrémentale, soit une sauvegarde totale hebdomadaire + une sauvegarde quotidienne de juste ce qui a été ajouté dans la journée.
RTO – le temps perdu acceptable
RTO est un acronyme qui signifie Recovery Time Objective. En français, Objectif de temps de reprise.
C’est clair ?? 😉
Bon, en clair le RTO, c’est le temps que l’on juge acceptable pour remettre en place une sauvegarde après un incident.
Prenons un exemple concret, avec un magasin en ligne.
Si le datacenter qui héberge mon site web brûle, je n’ai plus de site web. Donc plus de magasin, et plus d’information sur les commandes en cours et à qui le livrer.
Toute mon entreprise est à l’arrêt ! Ça peut avoir un coût énorme !
Ainsi je dois avoir un plan pour remettre en marche la machine, avec un objectif de temps acceptable pour remettre en place le service à partir d’une sauvegarde. C’est ce qu’on appelle le RTO.
Critères pour déterminer les ressources à allouer à ses sauvegarde
Sauvegarder des données coûte. Plus ou moins cher. Mais perdre ses données coûte beaucoup plus cher !
Il faut donc trouver un équilibre dans les ressources que l’on veut allouer à la sauvegarde de ses données.
Voici des critères:
- Fréquence d’utilisation
- Volume de données
- Criticité des données
- Vitesse d’accès à l’information
Intuitivement on va prendre en compte ces critères.
Voici des exemples:
Il est clair que des photos de ses vacances d’il y a 10 ans ne sont pas consultée tous les jours. La fréquence d’utilisation est faible. La criticité des données est importante dans la mesure où l’on ne peut pas reconstituer les données. Mais faible dans la mesure, où ce n’est probablement pas nécessaire à la poursuite de votre gagne pain !
Sauvegarder tout son poste de travail dans le nuage, c’est intéressant, tout est disponible de partout. Mais le jour où votre disque dur crash, il faut récupérer les données. C’est là que l’on découvre que le service de nuage utilisé limite la bande passante à disposition. Il faut trois semaines de téléchargement pour récupérer l’entier des données de son ordinateur. Donc ici le RTO est de 3 semaines !
Si c’est l’ordinateur qui permet de travailler au quotidien, c’est un soucis. Dans ce cas une sauvegarde complète locale et démarrable est plus utile. Il faut acheter support mémoire supplémentaire.
Quel support mémoire acheter. Un SSD c’est super rapide, mais plus cher qu’un disque dur. La fréquence d’accès à ses sauvegardes est plus rare, donc on peut se permettre un disque dur.
Si l’on sauvegarde d’énorme quantité de données, comme le font les chaines de télévision qui archivent leur diffusion. Ici on va privilégier les bandes magnétiques LTO, Linear Tape Open.
On peut acheter une cassette LTO de 15To pour ~CHF 50.-
Alors de quand date votre dernière sauvegarde ?
